Se tem uma coisa que me deixa mordido da vida por utilizar o Systemd é o seu comportamento. Recentemente tive péssima experiência com ele.
E o Systemd me deixando fulo da vida
Meu assunto sobre o Systemd, tanto no meu canal quando blog, começaram através do vídeo sobre a distribuição Debian. Veja abaixo a parte que menciono sobre o Systemd no vídeo do Debian:
Daí rolou todo aqueles boatos que o Systemd causa ameaça ao software livre e de código aberto. Sendo franco e imparcial sobre o assunto, todos esses assuntos não passam de especulação. Muitos nem mesmo sabiam que o Systemd já estava presente no Debian 7.
Esse assunto virou especulação tão grande que vi em fóruns internacionais o pessoal afirmando que o Systemd se trata de uma armadilha da Microsoft para acabar com o Software livre.... (ri muito)
Foi onde fiz o vídeo "O caso Systemd":
Resolvi fazer questão de utilizar o Debian para verificar o que o Systemd tem a oferecer. Na questão de boot mais rápido como proposto... sim, ele oferece um boot mais rápido. Pude notar isso do Debian 7 para o 8, mas agora vou expor a minha raiva sobre o Systemd.
Gostei dele, está funcionando bem (também, depois de anos de desenvolvimento, se não funcionasse bem, se joga da ponte), só que como qualquer outra daemon init faz... nada de inovador ao meu ver (ao menos, não ainda).
Pergunta feito a Linus sobre o Systemd, podemos ler o seguinte:
init system
Por lorinc
Não havia um kernel unix-like decente, você escreveu um que se tornou finalmente o mais utilizado. Não havia um software de controle de versão decente, você escreveu um que se tornou finalmente o mais amado. Você acha que já temos uma init system decente, ou você tem plano de escrever uma que vai finalmente se estabelecer no mundo nesse tópico quente?
Linus: Você pode dizer que a palavra "systemd", não é uma palavra de quatro letras. Sete letras. Conte-as.
Tenho que dizer, eu realmente não tenho ódio pelo systemd. Acho que ele melhora bastante no estado sobre init, e não, eu não me vejo aprofundando em toda essa área.
Sim, ele pode ter uns poucos cantos estranhos aqui e ali, e tenho certeza que você encontrará coisas a desprezar. Isso acontece em todo projeto. Não sou um enorme fan de binary logging, por exemplo. Mas isso é só um exemple. Prefiro muito mais a infraestrutura do systemd para a inicialização de serviços do que a da tradicional init, e acho que é uma decisão de projeto muito maior.
Sim, Tenho questões de personalidade com alguns dos mantenedores, mas isso é uma questão de como você trata de bug reports e aceita a culpa (ou não) para quando coisas vão erradas. Se as pessoas acham que isso siginificava que eu tenho antipatia ao systemd, terei que lhes desapontá-los, pessoal.
Agora, expondo o lado que o Systemd me deixa irritado, notei que ele apresenta uma falha ao atualizar o sistem. Após atualização utilizando aptitude safe safe-upgrade, algumas vezes o computador não desliga quando ao utilizar um dos comando:
$systemctl poweroff
#halt
#init 0
Da semana passada pra cá, já foram três vezes que isso aconteceu. Sendo franco, isso é muito irritante; não consigo desligar o computador em algumas ocasiões. Tenho que puxar o cabo, por que na tela consta que o sistema foi desligado, mas está la, o computador ligado.
O Pulse áudio, ficou muito a dever. Me da um trabalho conseguir uma qualidade razoável no áudio para os vídeos (o ALSA fazia isso melhor). Questão do boot rápido, ao meu ver foi simplesmente reinventar a roda, pois o OpenRC já fazia isso a bem mais tempo (e oferece boot bem mais rápido). Não sei por que não analisaram o OpenRC melhor antes de desenvolver o Systemd, talvez alguma questão na clausula 2 da licença BSD que poderia atrapalhar.
Bom, mas enfim, esse artigo foi um feedback a quem quiser saber mais sobre o Systemd. Ele é uma realidade (aceitemos ou não). Não deixem de ler o artigo sobre o introdução ao Systemd que eu traduzi direto da Linux Foundation.
Quinta, 06 de
Novembro de 2014 às 14:38. Carla Schroder. Exclusivo
cgroups, ou
control groups, estão presentes no kernel Linux há alguns anos, mas
não vem sido muito utilizado até o systemd.
Em tempos
antigos nós tínhamos runlevels estáticos. systemd tem mecanismos
para controle mais flexível e dinâmico do seu sistema.
Antes de entrarmos em mais aprendizado de mais
comandos uteis do systemd, vamos dar uma pequena viagem na estrada na
lembrança. Há essa esquisita dicotomia no Linux-land, onde o Linux
e o FOSS estão sempre avançando e progredindo, e as pessoas estão
sempre reclamando disso. É por isso que estou reduzindo todo esse
tumulto anti-systemd a um grão de sal, por que eu me lembro quando:
Pacotes eram
ruins, por que usuários de Linux de verdade construíam tudo a partir
do código fonte e mantinham controle estreito do que acontecia nos
seus sistemas.
Gerenciadores de resolução de
dependências (Dependency-resolving) de pacotes eram ruins, por que usuários de Linux
de verdade dependências manualmente.
Exceto pelo
apt-get, que sempre foi bom, então somente o Yum era ruim.
Por que a Red Hat
era a Microsoft do Linux.
Yxi Ubuntu!
Bú seu Ubuntu!
E por aí vai... como eu disse muitas vezes
anteriormente, mudanças são perturbadoras. Elas mexem com o nosso
fluxo de trabalho, que já não são coisas pequenas por que qualquer
rompimento tem um verdadeiro custo de produtividade. Mas nós ainda
estamos no estágio infantil da computação, então ela vai
continuar mudando e avançando rapidamente por um bom tempo. Tenho
certeza que você pessoas que estão presas na ideia de que uma vez
que você compra algo, como uma chave inglesa ou uma peça de mobília
ou um flamingo rosa ornamental de gramado, é para sempre. Essas são
as pessoas que ainda estão rodando Windows Vista, ou Deus no ajude
Windows 95 em algum PC antiquado, débil com um monitor CRT, e que
não entende por que você continua bugado-os para que sejam
substituídos. Ele ainda funciona, certo?
Que me lembra do meu grande triunfo em manter um
computador antigo rodando bem depois que ele deveria ter sido
aposentado. Era uma vez uma amiga que tinha esse 286 velhinho rodando
alguma versão inadequada do MS-DOS. Ela o utilizava para algumas
tarefas básicas como compromissos, diário, e um programinha velho
de conta que eu escrevi para ela em BASIC para seu registro de
verificação. Quem liga para atualizações de segurança, certo?
Ele não está conectado a nenhuma rede. Então de tempos em tempos
eu substituía o resistor e capacitor de falha ocasional, o
suprimento de energia, e a bateria CMOS. E continuava levando. Seu
velho e minúsculo monitor CRT ambar escurecia cada vez mais, e
finalmente ele morreu depois de mais de 20 anos de serviço. Agora
ela está utilizando um Thinkpad antigo rodando Linux para as mesmas
tarefas.
Se há uma moral nessa tangente ela me escapou,
então vamos nos ocupar com o systemd.
Runlevels vs. States
SysVInit utiliza runlevels estáticos para criar
states diferentes para bootar, e a maioria das distros utilizam
cinco:
Single-user mode
Multi-user mode
sem serviços de rede iniciado
Multi-user mode
como serviços de rede iniciado
System shutdown
System reboot.
Particularmente, Eu não vejo muito valor pratico
em ter múltiplos runlevels, mas lá estão eles. Ao invés de
runlevels, o systemd lhe permite criar states, que lhe dá
mecanismo mais flexível por criar configurações diferentes para
bootar. Esses states são compostos de múltiplos arquivos unit
empacotados dentro de targets (alvos). Os targets tem bons
nomes descritivos aos invés de números. Arquivos unit controlam
serviços, dispositivos, sockets, e montagens. Você pode ver como
esses arquivos se parecem ao examinar os targets prefab que vem com o
systemd, por exemplo /usr/lib/systemd/system/graphical.target,
que é o padrão no CentOS 7:
[Unit]
Description=Graphical Interface
Documentation=man:systemd.special(7)
Requires=multi-user.target
Conflicts=rescue.target
After=multi-user.target
[Install]
Wants=display-manager.service
AllowIsolate=yes
Alias=default.target
Então, como os arquivos unit se parecem? Espreitemos um. Arquivos
unit estão em dois diretórios:
/etc/systemd/system/
/usr/lib/systemd/system/
O primeiro é para nós atuarmos, e o segundo é
aonde os pacotes os arquivos unit. O /etc/systemd/system/leva precedência ao /usr/lib/systemd/system/.
Urrah, humano sobre a maquina. Esse é o arquivo unit para o servidor
Web Apache:
Esses arquivos são bem compreensiveis mesmo para recém-chegados ao
systemd, e os aquivos são bastante simples do que um arquivo
SysVInit init, como esse snippet a partir do /etc/init.d/apache2exibe:
SCRIPTNAME="${0##*/}"
SCRIPTNAME="${SCRIPTNAME##[KS][0-9][0-9]}"
if [ -n "$APACHE_CONFDIR" ] ; then
if [ "${APACHE_CONFDIR##/etc/apache2-}" != "${APACHE_CONFDIR}" ] ; then
Você pode visualizar as dependências unit, e
sempre é surpreendente para mim como eles são complexos:
$ systemctl list-dependencies httpd.service
cgroups
cgroups, ou control
groups (grupos de controle), tem estado presente no kernel Linux há
alguns anos, mas não tem sido muito utilizado até o systemd.
A documentação
do kernel diz: "Control Groups fornecem um mecanismo
por agregar/particionar conjuntos de tarefas, e todas as suas futuras
children, nos grupos hierárquicos com comportamento
especializado."Em outras palavras, ele tem o potencial para
controlar, limitar, e alocar recursos em múltiplos jeitos uteis.
systemd utiliza o cgroups, e você pode vê-los. Ele exibe sua arvore
de cgroup inteira:
$ systemd-cgls
Você pode gerar uma visualização diferente com o bom e antigo
comando ps :
$ ps xawf -eo pid,user,cgroup,args
Comandos uteis
Esse comando recarrega o arquivo de configuração
de uma daemon, e não seu arquivo de de serviço systemd. Utilize
isso quando você fizer uma alteração de configuração e quiser
ativar-lo como a menor descrição, como esse exemplo para o Apache:
# systemctl reload httpd.service
Recarregar um arquivo de serviço para-o completamente e reinicia um
serviço. Se não estiver rodando, Ele o inicia:
# systemctl restart httpd.service
Você pode reiniciar todas as daemons como um único comando. Isso
reinicia todos os arquivos unit, e re-cria toda a arvore de
dependência do systemd:
# systemctl daemon-reload
Você pode rebootar, suspender, e desligar como um usuário comum não
privilegiado:
Eu acompanho o desenvolvimento do systemd mais ou menos desde 2011, e confesso que me surpreendi com a sua evolução tão rápida. Passei a me dedicar a ter noção de como utilizá-lo de acordo com que saiam as informações em sites estrangeiros (o que não fica tão distante do SystemV em uma curva de aprendizado).
Systemd é um init system desenvolvido para substituir as mais conhecidas SysteV e BSD focando trazer um padrão para o Linux e melhor adoção do sistema operacional por parte de empresas e projetos.
Achei bem uma palhaçada quando escreveram o artigo boicotem Linux (que hoje não da para encontrar. PARABÉNS POR ISSO!) e todos os ataques que fazem a Lennart e a equipe do systemd. E foram esses ataques insensatos que me levaram a estudar o systemd. Uma das besteiras que eu li e ouvi foi que o systemd é uma conspiração de empresas que ameaçam o software livre (e li ate mesmo a BALELA de que o systemd é uma conspiração da Microsoft). Então aqui vai a real noção do que é o systemd.
Esses dias um grupo de uma distribuição que utiliza o runit no lugar do systemd ate vieram me falar que os bugs demoram a ser corrigidos... Apesar de funcional, há quanto tempo o desenvolvimento do runit está parado?...
Essa semana estive na Campus Party e me encontrei com a equipe da Endless (e eu e o Dionatan no conhecemos pessoalmente depois de longos anos de amizade. Finalmente né hehehehe). Aproveitamos inclusive para entrevistar Cosimo Cecchi que trabalhou na Red Hat, é um dos desenvolvedores do EndlessOS e é amigo particular do Lennart.
É interessante saber pois a galera costuma dizer que a Red Hat desenvolveu o systemd para aprisionar as pessoas; porém Cosimo nos contou que o systemd era um PROJETO PESSOAL do Lennart que a Red Hat rejeitou por longa data. Notaram como se aprofundar no assunto é importante? Ouçam como se não existisse certo ou errado.
No vídeo "O que é daemon init?" eu mencionei que existem várias daemons init (ou init systems) diferentes disponíveis. porém mencionei somente as (digamos) mais populares como o rc (run command) do Unix mais ou menos na versão 10 e que foi herdado pelos BSDs e pelo slackware, o SystemV (ou sysvinit que introduziu o conceito de runlevels que é uma especificação declarativa de serviço de sistema). O holandês Miquel van Smoorenburg é o autor da versão do sysvinit para Linux. Miquel fez também o primeiro port do Debian para a arquitetura Alpha e tem como símbolo um Tux bebinho de tudo).
Olaunchd do Mac OS X, o OpenRC originado no Gentoo, o Upstart originado no Ubuntu e o systemd originado no Fedora. O vídeo pode ser conferido logo abaixo:
Então por que não debater sobre outros init systems diferentes? Vale começar pelo NetBSD que, como mencionei no vídeo, o NetBSD migrou da init BSD para uma versão da SystemV.
O Solaris possui o SMF (Service Management Facility= Facilidade de Gerenciamento de Serviço que também é uma das inspirações para a criação do systemd). Esse init system faz uso de arquivos XML ao invés de init scripts, é utilizado no IllumOS (já que é um fork do antigo OpenSolaris) e no OpenIndiana que é uma distribuição derivada do IllumOS. Agora, vamos a mais um monte de outros init systems.
Quero começar com rc específico do Plan9 (não confunda com o rc dos BSDs e do Slackware) que é um shell que soluciona o problema de white space que ocorrem em outros shell no padrão POSIX (como o bash). O que acontece é que os scripts de outros shells quebram caso os nomes dos arquivos possuam espaço como no exemplo:
for i in *.jpg; do
cp $i /tmp
done
Já o plan9 rc lida com esse problema utilizando um recurso chamado Free Carets inserindo o operador ^ automaticamente entre as palavras. O Plan9 rc possui sintax diferente mas um exemplo de como ele soluciona o problema pode ser conferido abaixo:
É um init system alternativo que incorpora as ideias da sysVinit, do simpleinit, do daemontools e do make que visa cuidar de processo paralelo (assim como o systemd e o launchd), dependências, roll-back, pipelines, melhorias no signaling e desmontar filesystems no desligamento (assim como o systemd possui recurso parecido). Falando em desmontar no desligamento, no dia 20 de agosto foi adicionado ao Systemd a ferramenta para montar filesystems. O interessante é que o Depinit possui comando parecido com o systemctl do systemd chamado depinctl. O Depinit, está sob licença GPLv2 e ainda está em fase experimental sendo disponível para Linux e FreeBSD. Sua ultima versão foi lançada em maio de 2014 (a versão 0.1.4).
É um init Unix Cross-platform com supervisão de serviço operando em três estágios obtidos em /etc/runit. Ela está disponível para Linux, FreeBSD, Mac OS X e Solaris e pode ser facilmente adaptada para outros Unixes. Os direitos autorais são reservados ao desenvolvedor da daemon. Hoje essa daemon é adotada pela distribuição Void Linux e tendo também suporte do Busybox.
É possível utilizar runit sem substituir o atual init system que estiver utilizando em sua distribuição simplesmente executando o stage 2 do runit como um serviço do seu atual init.
É uma alternativa a implementação do /sbin/init para Linux e FreeBSD, mas parece que anda em decadência. Apesar disso, é um bom init para dispositivos embarcados e é bem modular. possui runlevels nomeados modes que é descrito em um arquivo XML a parece-se um pouco com a runlevel do Gentoo.
É a daemon init da distribuição Turka chamada Pardus. É uma versão paga do Linux pelo que me lembro de ter visto anos atrás. É difícil conseguir informações nesse site desde que não possui versão inglesa (parece que os caras não querem mais nenhum outro país por lá rsrs. Essa seria uma boa distribuição para entrar para os "50 lugares onde Linux está rodando e você nem faz ideia), mas essa init trabalha com um subsistema init chamada Mudur que é escrito em python e um sistema de gerenciamento de configuração chamado Çomar.
É um init system para Linux na versão do kernel 2.6. Foi projetado tendo como foco a facilidade na configuração e a não intromissão, ser pequeno para funcionar tanto em distribuições grandes e minimas. Esse init não possui dependências externas além da biblioteca C, dos pthreads do kernel e sugerido um /bin/sh funcional. Ele possui um sistema de logs para boot, runlevels em ASCII, um único arquivo de configuração conveniente; recursos automáticos como hostname e montagem do sistema de arquivos virtual (como o /proc) e vários outros recursos. Vale a pena conhecer esse init system:
É uma daemon (ainda em versão beta) feita pelo alemão Felix von Leitner, mesmo criador da dietlibc e do embutils. Além de visar ser minuscula (característica típica do Felix e que faz isso muito bem) também visa corrigir alguns erros cometidos pelos init systems tradicionais no Linux. Se quiser saber mais sobre a diet libc e do embutils, assista o vídeo abaixo:
O processo de boot das típicas distribuições Linux é muito sofrido
Se um boot script falhar, todo o processo de boot é interrompido
Se um serviço for interrompido via o comando kill, ele não é automaticamente reiniciado (se tornando um processo zumbi)
O script de shutdown não sabe qual o PID da daemon (modos de falhas horríveis onde você acidentalmente mata o processo errado)
E a falta de flexibilidade (iniciar mais um ou um serviço a menos?).
No minit, cada serviço possui seu próprio diretório dentro de /etc/minit contendo dependências e dentre outros recursos. Dentre os problemas a serem solucionados pelo minit estava o de reduzir o período de downtime (que é também uma das ideias do systemd).
cinit é um init system com recursos de dependência e suporte a perfil que foi baseado no design no minit. Devido o minit não possuir suporte a dependências reais (o que leva a você não saber se o serviço que você depende foi realmente iniciado) e seu conceito de dependência ser lento, o suíço Nico Schottelius para suprir estas necessidade.
O cinit possui características semelhantes ao systemd: parallel execution; profile support que além de serem fáceis de criar você ainda pode especificar quais serviços iniciar (o que me lembra o conceito de units do systemd).
dinit é desenvolvido por Davin McCall, um ex contribuidor do kernel Linux e do Mesa driver. Assim como cinit e o runit, o dinit foi desenvolvido para ser integrado a outros ao invés de substituí-los (apesar que runit ainda permite substituir outros init systems). dinit é utilizado no Chimera Linux e é uma das várias escolhas do Artix Linux.
Também desenvolvida na Alemanha, trabalha utilizando seu próprio filesystem baseado em esquema de serviço e é escrita em C++. Ainda não é muito bem testada.
s6 é descrito como um pequeno conjunto de programas para UNIX, projetado para permitir supervisão de processos (a.k.a service supervision), na linha do daemontools em conjunto com runit, assim como várias operações em processos e daemons. As ferramentas do s6 são independentes que podem ser utilizadas com ou sem framework e podem ser agrupadas.
O s6 é o init system padrão da distribuição Glaucus. A skarnet disponibiliza também o s6-linux-utils que faz parte do ecossistema s6 e é utilizada para criar init system baseado no s6 no kernel Linux. É possível também ter um s6-linux-utils multicall.
Foi desenvolvido para a distribuição ObaRun, um fork da distribuição Arch desenvolvida por um anônimo como uma alternativa ao systemd. Na verdade o 66 é um fornecedor de gerenciamento de serviços para o s6 e não um init system em si.
Esse é um init e gerenciador de serviços escrito na linguagem Rust por Danilo Spinella, um desenvolvedor italiano da Suse inspirando-se no 66, no s6 (já mencionado anteriormente) e no daemontools mencionado a seguir. Ainda é um trabalho em progresso e o autor descreve que você o utiliza por conta e risco. Inicialmente se chamava tt e era escrito em C++. Possui uma sintaxe muito parecida com a do systemd. Está sob licença GPL3+, o que eu acho uma bela de uma burrice.
Também desenvolvido por Danilo Spinella o tt é um gerenciador de serviço init também inspirado no 66, s6 e no deamontools, para substituir o systemd mas oferecendo melhor base de código que o 66. A ideia é realmente reescrever o 66 já que este possui muitos bugs difíceis de serem corrigidos. A princípio parece que iria ser escrito na linguagem porém, em seu github vamos que é escrito na linguagem C++.
As próximas não são init systems. Na verdade se tratam de ferramentas que servem como auxiliares de init systems. A daemontools foi desenvolvida por Dan Bernstein como uma coleção de ferramentas para o gerenciamento de serviços de sistemas operacionais da família Unix (eles iniciam o serviço e o reiniciam caso ele morra. Parecido com o que temos no systemd). Esta ferramenta é fortemente utilizada em conjunto com o runit e o minit. Do daemontools surgiu um derivado chamado daemontools-encore que adiciona várias melhorias e mantendo compatibilidade entre ambos.
Nesse meio ainda temos o nosh que tem a mesma função que o daemontools. nosh foi desenvolvido originalmente para suprir a falta de opções que os BSDs não possui como as do launchd, systemd e do upstart. A equipe do nosh queria algo mais do que outras daemontools oferecem.
No meio disso, parece que teremos em breve algo similar no toybox que hoje traz os comandos init e oneit.
A ultima que eu gostaria de mencionar é a perp (abreviação de "the perpetrator"). Infelizmente, sua ultima versão foi em 2013.
sninit é uma pequena implementação para Linux que visa ser um substituto para o systemV sendo mais limpo e mais confiável, fornecendo melhor controle de processos removendo a necessidade de init scripts. Também é menor que o systemd para distribuilções que dependam do comando systemctl. O projeto sinit foi concluído sendo agora a continuidade no minibase.
procd é a daemon do OpenWrt sistema operacional Linux que utilizamos em nossos roteadores escrito em C. Ele mantem rastreio de processos iniciados a partir de seus init scripts (via ubus calls), e pode suprimir solicitação de inicialização/reinicialização de serviço redundante quando o ambiente de configuração não for alterado.
Conclusão
No Linux, tudo é uma questão de escolha. Não quer utilizar uma interface gráfica, você utiliza outra; não quer utilizar um terminal, utiliza outro. O mesmo vale para sistema de arquivos, gerenciadores de pacotes tanto de baixo quanto de alto nível, empacotamentos e todos os tipos de ferramentas, inclusive init systems. Isso é OS VÁRIOS SABORES DE LINUX.
Existe também por exemplo a Twsinit que é desenvolvido em Assembly, é bem pequena (exige somente coisa de 8k de memória) e ser uma substituição das atuais; a do Fedora chamada FCNewInit e Serel que também foca em acelerar o boot.Bom, acho que está bom o tamanho da lista. Vale mencionar (mais uma vez, assim como mencionado no vídeo "O caso Systemd") que do Systemd surgiu o fork UselessD, mas que não conseguiram atingir o seu objetivo proposto.
Moral da história é que acelerar o boot, reduzir o shutdown melhorando assim o uptime e solucionar os problemas gerados pelos scripts já é um desejo antigo. A maioria das aqui mencionadas focaram esforços para poder trazer essas soluções. Criticar o systemd então se torna somente uma questão de birra. E no meio de um oceano repleto de init systems, o inútil debate criticando o systemd continua até hoje. Como sempre, os argumentos são os mesmo e os piores imagináveis:
"ele não é portável", "ele é incompatível com init scripts" (o que não é verdade), "Ain, logs binários", "systemd faz muitas coisas, isso é contra a filosofia", "systemd é uma ameaça ao sistema operacional", "vou contar para a minha mãe"...
E porque ficar com essas discussões se temos a liberdade de adotar o que quisermos? ISSO É LIBERDADE DE VERDADE. Por que o systemd deveria ser portável se outros init systems já são? Alias por que criticar o systemd sendo que outros já tentaram implementar os mesmos recursos? Não quer utilizar o systemd? Neste artigo está um catalogo bom para você desfrutar; basta partir para os estudos.
Fico por aqui, espero ter agregado mais conhecimento. Forte abraço e até a próxima.
Open Embedded trabalhando para que systemd tenha suporte a musl
Desde antes do lançamento do Debian 8 que eu venho debatendo sobre o systemd, principalmente por terem criado um monte boatos (vergonhosos e mentirosos) para poder criticar o novo init system. De lá para cá eu já fiz videos contando a sua história, debatendo bug encontrado, fiz live debatendo a palestra "A tragédia systemd" feita por um dos desenvolvedores do FreeBSD e fazendo até mesmo parte do meu curso (não deixe de conferí-lo hein ;)
Há algum tempo atrás eu fiz um vídeo detalhando as criticas tenho a respeito do systemd. Sim, eu tenho minhas criticas a respeito do systemd assim como tenho a respeito de qualquer outra ferramenta e que não tem nada a ver com os boatos que todos dizem a respeito do init system. Quer saber as minhas criticas? Confere o vídeo aí embaixo:
Recentemente descobri que a Open Embedded trabalha em um patch para que o systemd passe a ter suporte a musl (clique aqui para conferir) que é algo muito interessante de se ver já que o systemd é também adotado em embarcados. Isso já é um passo e há muito trabalho a ser feito já que a glibc possui incompatibilidade com as várias outras bibliotecas além da musl (dietlibc, uClibc e newlib). Esse é o motivo da musl não ter sido adotada ainda como biblioteca padrão no Debian mesmo havendo planos para isso. Há muito trabalho ainda a ser feito por parte da Open Embedded e dos colaboradores no desenvolvimento da musl, mas o futuro desta biblioteca é muito promissor (principalmente por sua qualidade de código e resultado no tamanho final dos binários).
Mas ainda espero que o systemd também venha a ter suporte ao LLVM/Clang e longa vida ao systemd.
Postado no site Linux Journal no dia 21 de Maio de 2026 por George Whittaker, que devido o crescimento de compatibilidade de software com o systemd, especialmente em torno de aplicações desktop, containers e programas de orquestração de container, aplicações flatpak, aplicações proprietárias, agentes de monitoramento, certas ferramentas de jogos e multimídia, AI e ferramentas enterprise começa a surgir uma pressão para que os desenvolvedores da distribuição Alpine Linux se adaptem a nova necessidade.
Apesar de a equipe do Alpine Linux intencionalmente evitar o systemd, trazendo assim vantagens e desvantagens para a distribuição, as desvantagens com as incompatibilidades começaram a ficar muito problemáticas já que as aplicações empregam fortemente a libsystemd, as APIs do systemd e os comportamentos específicos da glibc (sim, no meu artigo Linux: mais do que um Unix eu mostro uma parte considretável de recursos da API do Linux, a LSB (Linux Standard Base), que agrega recursos e funcionalidades ao Linux que nenhum outro Unix ou a API POSIX possui. Estes recursos foram basicamente concentrados dentro da glibc ao ponto que eu relato em meu artigo Muito além do GNU: Os vários sabores de bibliotecas C que a "glibc é escrita com nada além do Linux em mente"; o que eu considero uma extrema burrice terem feito isso pois deveriam ter feito o mesmo em paralelo a outras bibliotecas como alternativas e não deixando o Linux escravo da glibc. Eu tenho artigo intitulado O que falta para a que a musl substitua a GilbC no Linux que já detalha bem o assunto e espero que um dia isso venha realmente acontecer.
Como o ecossistema do Linux em torno do systemd cresce cada vez mais, alguns esforços experimentais para empacotar porções do systemd sem a necessidade de ter o Alpine Linux totalmente com systemd já estão sendo feitas assim como uma versão em paralelo do systemd com suporte a musl (já que compatibilidade da glibc na musl já existe). O que são ideias interessantes demonstrando que o Alpine não está abandonando a sua identidade de manter a distribuição mínima e sim se adaptando e se modernizando. A ideia de compatibilidade é a chave para isso assim como outros projetos no Linux fazem (Wayland com o X11, proton e o Wine com as aplicações Windows e etc).
No artigo "O que define um Unix?" mostrei que Linux é um legitimo Unix, mas uma coisa que muita gente não sabe é que Linux se tornou mais do que um Unix possuindo sua própria API. Quando analisei o ext4 do HelenOS para descobrir se tratava-se do próprio filesystem do Linux ou feito do zero, uma das coisas que eu fiz foi exatamente tentar identificar em seu código algo específico do Linux. Para se ter uma ideia do que estou falando, reparem as linhas #include dos arquivos balloc de ambos os Ext4:
Arquivo balloc.c do Ext4 do Linux
Arquivo balloc.c do Ext4 do HelenOS
Interessante MAS... para que possuir uma API própria se Linux já é um sistema operacional Unix? Ou seja, ele possui suporte as especificações POSIX e SUS assim como todos outros Unix. Para responder a essa pergunta é interessante ler a respeito dos mitos sobre o systemd que Lennart publicou em seu blog. E é aí que chegamos no mito de número 16:
16. Mito: systemd não é portável por razão nenhuma.
Sem sentido! Utilizamos funcionalidade específica do Linux porque precisávamos dela para implementar o que queríamos. Linux possui tantos recursos que UNIX/POSIX não possuíam, e queríamos capacitar os usuários com esses recursos. Esses recursos são incrivelmente uteis, mas somente se eles são expostos de verdade de um jeito amigável ao usuários, e é isso o que fazemos com o systemd.
FOSDEM: Qual funcionalidade específica do Linux que o systemd utiliza e qual a vantagem dessa sobre uma solução que é portável para outros sistemas operacionais?
Lennart Poettering: Há um monte de funcionalidades específicas do Linux que confiamos. A primeira que vem a mente provavelmente é o cgroups (abreviação de Control Groups) que é um recurso do kernel Linux que pode ser usado para criar processos de grupos hierárquicos, criar label para esses e opcionalmente aplicar limites de recurso ou outras regras para tais. Mas há mais um monte. O systemd íntegra muito bem com o sistema udev que é específico do Linux para eventos hot-plug. Outra, a solução para disk read-ahead incluímos nos usos do systemd, a fanotify() call também específica do Linux. Ou adicionamos suporte a processos spawning em seus próprios namespaces ou com definições limitadas de capacidades, ambas nas quais são features específicas do Linux. Ou adicionamos suporte ao automouter específico do Linux e outras APIs mount tal como polling mount changes via /proc/self/mountinfo na qual não existe em outros sistemas operacionais. Internamente nós utilizamos um monte de API calls mais novas, como a timerfd() ou signalfd() que não estão disponíveis fora do Linux. Essa últimas calls puderam ser emuladas em outros sistemas operacionais, mas utilizá-las simplifica muito o nosso próprio código. E muitos outros features do Linux que utilizamos não possuem contrapartidas adequadas em outros Unixes.
Não ter que se importar com portabilidade tem duas grandes vantagens: podemos fazer máximo uso do que o kernel Linux moderno oferece nesses dias sem dores de cabeça -- Linux é um dos kernels mais poderosos existentes, mas muitos de seus features não tem sido utilizados pelas soluções anteriores. E segundo, ele simplifica muito bem nosso código e o torna menor: desde que nunca precisamos abstrair interfaces do sistema operacional, o montante de Código grudado (glue code) é mínimo, e consequentemente o que ganhamos é uma chance bem menor de gerar bugs, uma chance bem menor de confundir o leitor do código (consequentemente melhor manutenção) e uma footprint bem menor.
Muitos dos meus projetos anteriores (incluindo PulseAudio e Avahi) foram escritos para serem portáveis. Sendo aliviados das correntes que a exigência por portabilidade coloca em você é um tanto libertador. Enquanto que garantir portabilidade quando se trabalha em aplicações de alto nível não é necessariamente um trabalho difícil, se torna crescentemente mais difícil se a coisa na qual você trabalha é um componente do sistema (os quais o systemd, o PulseAudio e o Avahi são).
De fato, o jeito que eu vejo as coisas na API do Linux anda tomando o papel da API POSIX e o Linux é o ponto focal de todo o desenvolvimento de software livre. Devido a isso eu só posso recomendar aos desenvolvedores que tentam hackear somente com Linux em mente e experimentar a liberdade e as oportunidades que ele lhe oferece. Então, obtenha uma cópia do "The Linux Programming Interface", ignore tudo o que ele diz sobre compatibilidade POSIX e parta para a hack em seu surpreendente software Linux. É bastante aliviante!
FOSDEM: Qual é o ponto chave do systemd?
Lennart Poettering: Não há apenas um, há vários. Já que eu não consigo listar, eu vou mencionar um único. Um que provavelmente surpreende muitos leitores: systemd é o primeiro init system do Linux que lhe permite matar um serviço corretamente. Surpreso com essa declaração? Mas é verdade. Matar uma daemon no Linux é realmente difícil e sem systemd é na verdade quase impossível fazer isso corretamente. (Não, um simples "killall httpd" é devido a muitas razões inadequadas de matar o Apache). Se você quiser saber porque, eu digo o que o systemd faz diferentemente aqui...
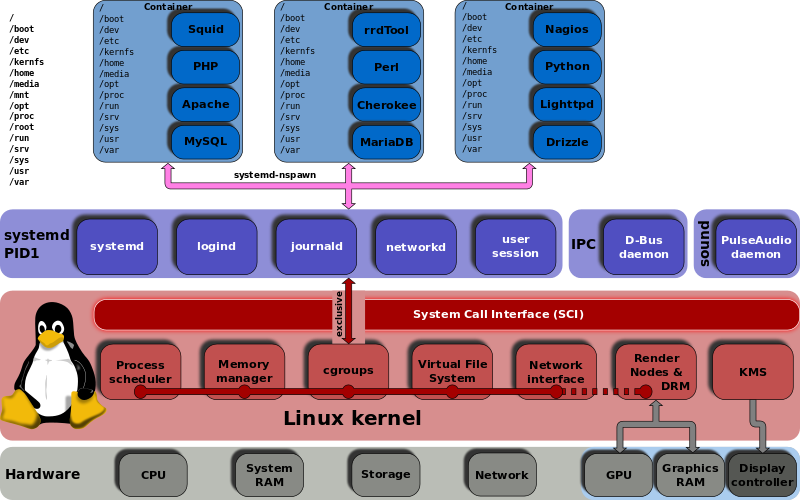
Agoraque já temos algum ponto de referência, podemos trabalhar em nosso estudo sobre tais recursos. Vou abordar mesmo os já mencionados por Lennart. Lembrando que se trata de pontos da parte de desenvolvimento, mas também irei tratar sobre tais recursos de acordo com a visão de um sysadmin e de usuários comuns (já que também é a razão pelas quais esses recursos existem).
Já mencionado anteriormente, esse recurso foi inicialmente desenvolvido por engenheiros do Google com o nome de Process Container.
E para evitar confusão com container, seu nome foi alterado (vale
lembrar que quando falamos de container, não estamos tratando unicamente
de Docker. O Red Hat Enterprise Linux 8 adota diferentes soluções de containers).
No vídeo A Tragédia do systemd, Benno Rice (desenvolvedor do FreeBSD) menciona que a comunidade FreeBSD tem como argumento "mas nós temos o Jails no FreeBSD".Benno responde:"Sim tem, mas o Cgroups é muito mais granular, muito mais flexível."Além do systemd, o cgroups é utilizado por projetos como o Docker, oFirejail, oLXCelmctfy.
É uma ferramenta para carregar aplicações e daemons sob demanda (somente quando os serviços são necessários), simplificar a forma como as aplicações se comunicam, ajudar a coordenar o ciclo de vida dos processos e tornar mais simples e mais confiável de codificar aplicações single instance ou daemons. A lista de projetos que fazem uso do D-Bus é enorme (em torno de uns 210 projetos no momento em que escrevo sobre o D-Bus) e podem ser conferidos clicando aqui.
Dado como a base fundamental dos containers, namespace (man 7 namespace) isola um recurso global do sistema em uma instancia tornando-o invisível a outros processos. Foi inspirado no Name Space do Plan9 (como sempre, o Plan9 contribuindo bastante).
O Docker é a ferramenta mais famosa a utilizar o namespace (uma vez que o Docker faz na verdade, uso de ferramentas já existentes no Linux. E sim, Docker é especifico para Linux assim como o systemd).
Netlink é o responsável por realizar a comunicação (transferência de informações ou troca de mensagens) entre o kernel space e o user space (kernel space e user space é inclusive uma parte essencial que eu tratei no meu artigo 5 diferentes modelos de kernel).
É composto por interface de sockets para processos do user space e uma API interna do kernel para os módulos do kernel. Também pode ser utilizado como IPC (InterProcess Communication) para permitir processos compartilharem dados entre si.
O Netlink é uma ferramenta fundamental para o funcionamento Iproute2. tanto que em versões anteriores das distribuições como é o caso RHEL 6 (que tinham o Net-tools como padrão), além de ser necessário instalar o Iproute2, era também necessário configurar e compilar um novo kernel já que não vinham com a maioria dos recursos de controle trafego por padrão.
Abreviação de fast user-space locking, futex é a base para a construção de fast user-space locking, semaphores, mutexes, variáveis de condições, read-write locks, barriers, e semaphores. No caso o que o futex faz é coordenar o trafego das comunicações no user spcace. futex syscall surgiu no kernel Linux 2.5.7 e foi adicionado no OpenBSD 6.2, passou a ser emulado pelo FreeBSD (Algo também para o NetBSD) e implementado no Windows 8 e Windows server 2012 sob o nome de WaitOnAddress function (synchapi.h).
A musl possui suporte a vários desses recursos (conferir a linha Various Linux extensions. Linux extensions referem-se a kernel interfaces fornecidas pelo Linux fora do scope da POSIX e como o epoll, signalfd, extended attributes, capabilities, carregamento de módulo e assim por diante).
O autofs é uma daemon utilizada para montagem automaticamente dos sistemas de arquivos (o que pode incluir sistemas de arquivos de rede, CD-ROMs, floppies e etc.) sob demanda através do automount e desmontá-los depois de um tempo que não estiver utilizando. A intenção do autofs é economizar recurso computacional e melhorar o desempenho (tentando evitar o uso do /etc/fstab).
Abreviação de Secure Computing, o Seccomp serve para tornar o acesso a uma thread mais restrita à um numero pequeno de syscalls. De forma mais simples de entender, podemos dizer que o Seccomp é uma Sandbox. O Seccomp faz uso da system call BPF (Berkeley Packet Filters. man 2 bpf) como uma espécie de filtro para os programas. Há também a libsecomp que provê meios de facilitar o uso do Seccomp e do BPF.
Iniciado no kernel 2.2,Linux Capabilities servem para verificação de permissões. São atributos especiais do kernel Linux que garantem privilégios administrativos específicos à processos e à binários que geralmente são reservados e destinados ao ID 0 (ou seja, o usuário root). O que o Capability faz é dividir os privilégios do usuário root em pequenas partes (em unities) garantido assim ao processo privilégios específicos e não todo os privilégios que o usuário root possui (algo parecido com o SUDO ou com os bits especiais, só que de forma mais restrita). Há em torno de 40 capabilities implementadas até o kernel 5.10.
Surgiu no kernel 2.6 como substituto o antigo devfs oferecendo uma base mais limpa e mais robusta de gerenciamento dos diretórios no /dev. O sysfs também surgiu o kernel 2.6 que é gerenciado pelo kernel para exportar informações básicas sobre dispositivos conectados recentemente sendo montado no diretório /sys (o udev pode fazer uso de informações do sysfs para criar device nodes correspondentes ao hardware relacionado).
O systemd-udev faz uso de instruções especificadas na regras do udev. Uma boa base de leitura sobre gerenciamento de dispositivos com o systemd-udev é esta aqui.
Evdev
Como descrito em sua manpage, o evdev é um driver do Xorg que cuida dos eventos de dispositivos de entrada em /dev/input. Possui suporte a mouse, teclado, tablet e touch‐screen. Existem também a libevdev e evdev para as linguagens Go e Python.
O ALSA (Advanced Linux Sound Architecture, traduzido para português do Brasil como Arquitetura Avançada de Som do Linux) é o servidor de áudio (e framework) responsável pela parte de áudio do Linux. O ALSA gerencia o acesso a placa de som (as interfaces de áudio) e permite que outros programas como esd, aRTs (descontinuado), JACK e o PulseAudio façam acesso às interfaces.
Foi o substituto do antigo OSS (Open Sound System) da 4front Technologies(apesar que seu ultimo lançamento foi em 2019 para o kernel 4.15). Eu e um amigo debatemos o motivo desta transição em uma série chamada Assunto games (bastando clicar aqui) e lá o Anderson explica as limitações que ocorriam no OSS.
DRM é um módulo do kernel que permite acesso direto ao hardware (algo parecido com o que acontece com sistema operacional exokernel). Surgiu no kernel Linux 2.2.18, o DRM fornece vários serviços gráficos a drivers de vídeo (que incluem gerenciamento de memória, gerenciamento de saída, de framebuffer, serviços de DMA e muito mais) através da biblioteca libdrm. O DRM também fornece gerenciamento a monitores através do Kernel Mode-Setting (KMS).
O DRM é tão interessante que foi portado para o DragonflyBSD como pode ser lido no texto abaixo:
A API epoll permite as aplicações monitorarem múltiplos descritores de arquivos para determinar quais descritores estão preparados para realizar entrada e saída de forma mais eficiente que as antigas syscalls select() e poll() que apresentavam ser pobres para as aplicações de redes modernas, ter pobre desempenho devido ao seu design e entregavam ao kernel uma lista completa com todos os descritores de arquivos (que a cada chamada, tinha que ficar reexaminando a mesma lista). epoll Essa é uma das dependências do Wayland. O FreeBSD possui um recurso similar chamado kqueue. O NetBSD também possui possui patches para o kqueue no pkgsrc mas que na época que anunciaram que planejavam portar o Wayland, essses patches não haviam sido aceito upstream.
O propósito do timerfd é que, uma vez que uma API se torna disponível no user space, ela deve possuir suporte indefinidamente para todos os propósitos sem quebrar as aplicações. Já que há vezes que essas regras são quebradas, mesmo em áreas conhecidas para distúrbios como o sysfs, para isso foi criado o timerfd e assim manter maior integridade dos arquivos.
O timerfd permite que uma aplicação possa obter os descritores de um arquivo para utilizar com eventos e assim eliminar a necessidade de sinais (signals). Já o signalfd é o responsável por criar descritores que podem ser utilizados para aceitar os sinais. Os sinais a que me refiro são por exemplo utilizados no comando kill como podem ser conferidos na manpage man 7 signal.
Linux Security Module (LSM) é um framework de segurança ao kernel. São na verdade extensões de segurança do kernel e não módulos que fornecem interface de politica de segurança MAC (Mandatory Access Control). Dentre eles temos o SELinux (o mais famoso deles sendo utilizado por padrão pelo RHEL, o Fedora e o CentOS); o AppArmor utilizado por padrão no Debian, o LoadPin, o Smack, o TOMOYO, o Yama e o SafeSetID.
O Integrity Measurement Architecture (ou simplesmente IMA) serve como subsistema de integridade do kernel que detecta se arquivos foram alterados acidentalmente ou maliciosamente, sejam remotamente ou localmente. O IMA faz parte dos módulos LSM anteriormente mencionados.
Fanotify também conhecido como o fscking e anteriormente conhecido anteriormente como TALPA, tem como propósito principal servir de scanner de malware no Linux (viruses, root kits, spyware, ad-ware e etc...) "Ué, mas Linux não tem vrius" (sabe de nada inocente). Surgiu na Red Hat em 2008 devido na época o kernel Linux não oferecer uma interface completamente adequada para implementar tais soluções de segurança. Esta ferramenta foi desenvolvida inclusive para atender as necessidades de muitas empresas que fornecem serviços de ati-malware.
A maioria dos apaixonados afirmam que Linux não é um Unix. E honestamente elas estão certas; Linux não é um Unix; Linux é mais do que um Unix. Linux não se limitou somente a o que todos os outros os Unix são ou tinham a oferecer. Linux resolveu explorar melhor o seu potencial.
Além de ser melhor do que muitos sistemas operacionais em várias áreas (SMP, desempenho, redes, virtualização e muitas outras áreas), ainda agregou recursos que o permitem abranger áreas que seriam inimagináveis a outros sistemas operacionais.
No artigo "The Hurd and Linux" do site gnu.org é descrito que Linux é arquiteturalmente igual ao kernel Unix e que o trabalho do projeto GNU se direciona a algo muito mais poderoso. O argumento apresentado por Richard Stallman baseia-se na proposta da arquitetura do microkernel (caso não entenda o que é microkernel, sugiro a leitura do meu artigo sobre 5 modelos diferentes de kernel) e que até hoje não aconteceu. Treze anos depois do lançamento do Linux, foi escrito o livro Open Life (traduzido pra inglês por Sara Torvalds, a própria irmã de Linus torvalds) e até então, nada do Hurd se apresentar... Mais de dezesseis anos depois do lançamento do livro Open Life, e o Hurd ainda não demonstra nem sinais de lançamento de uma versão estável. Não adianta acreditarem que o micrkernel é algo mais poderoso focado simplesmente no isolamento do kernel e carecendo de recursos.
Não dá para debater todos os recursos aqui neste artigo pois, como Michael Kerrisk descreve em seu livro Linux programing Interface, são mais de 500 system calls e library functions e acredito que tudo isso já serviu de uma boa abordagem para entender como Linux é poderoso.









")











 com um ativo port do Linux, lentamente trazendo DragonFlyBSD a padrões modernos. A partir de 2015, o suporte total a aceleração 2D/3D e vídeo ficaram funcional com o Xorg. Mais ou menos na mesma época, também houve um esforço concentrado para atualizar o sistema de som com uma grande porta HDA do FreeBSD. Gráficos, Video, e audio tornaram DragonFlyBSD em um desktop agradável.")





